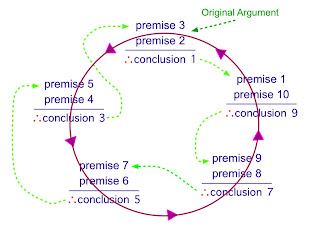
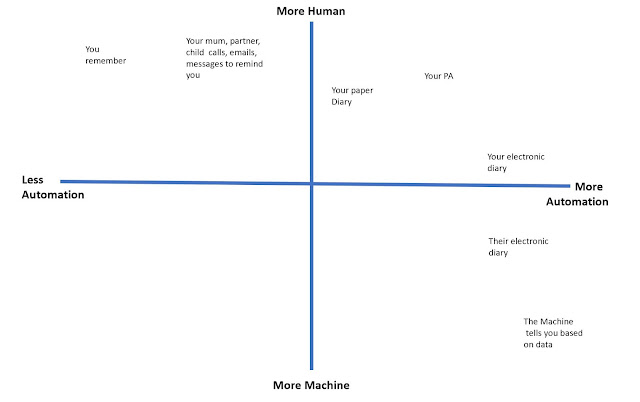
Mapping the different views of privacy ( public vs private) and why one identity makes no sense

Plotting your view of private self to a public self, against wanting to be more private as a citizen or more public as a person. Broadcast ( where you are public figure) Identity in the form of recognition Professional ( have to be known and have a status) Identity in the form of reputation Obscurity ( ability to hide in plain sight) Identity I am who I say I am (or others) Privacy Laws (where so much case law exists) Identity in the form of want to hide and have protection